Kube API
After reading this post, you will have:
- Understood the responsibilities of the kube-API server.
If you want to get the most out of this post I would highly recommend my article that briefly overviews the kubernetes architecture. Link Here
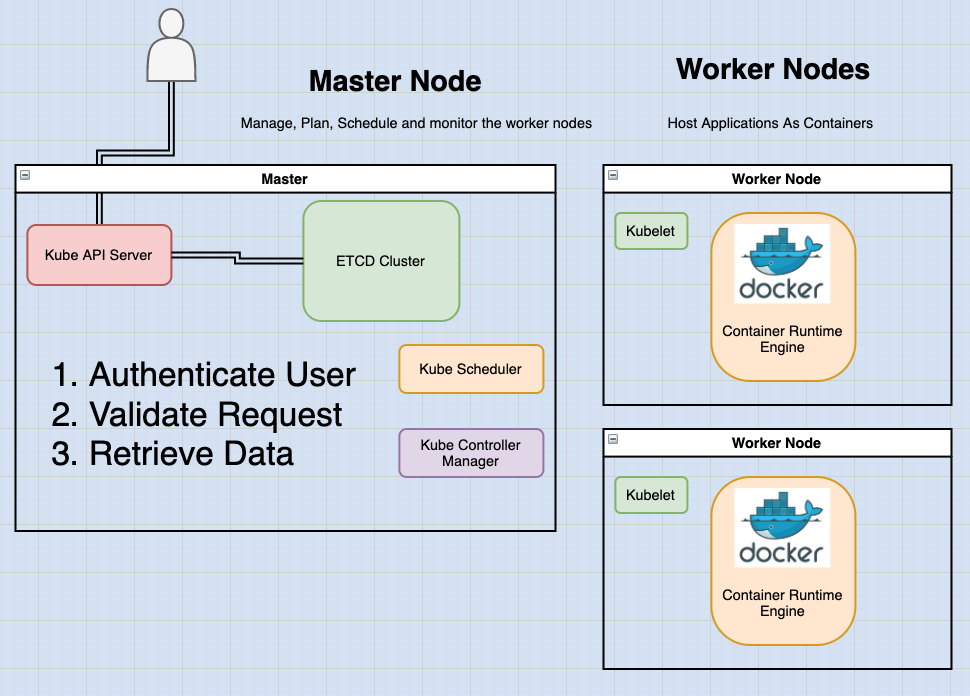
Earlier in this series, we discussed that the kube-API server is the primary management component in kubernetes.
When you run a kubectl command, the kubectl utility is reaching to the kube-API server.
Under the Hood
The kube-API server first authenticates the request and validates it. After, it proceeds to retrieve the data from the ETCD cluster and responds back with the requested information.
It's not compulsorty to use the kubectl command line to access the kube-API. Instead, you could also communicate with the API directly by sending a POST request. However, this is not as common as using the CLI.
A Common Scenario
Let's look at an example of creating a pod. As before, the request is first authenticated, and then validated.
In this case, the kube-API server does several things:
- It creates a POD object without assigning it to a node.
- Updates the information in the ETCD server.
- Informs the user that the POD has been created.
Thereafter, the scheduler continuously monitors the API server and realizes that there is a new pod with no node assigned. The scheduler identifies the right node to place the new POD on and communicates that back to the kube-API server.

The API server proceeds to updates the information in the ETCD cluster. The API server then passes that information to the kubelet in the appropriate worker node.
The kubelet then creates the POD on the node and instructs the container runtime engine to deploy the application image.
Once done, the kubelet updates the status back to the API server and the API server then updates the data back in the ETCD cluster.
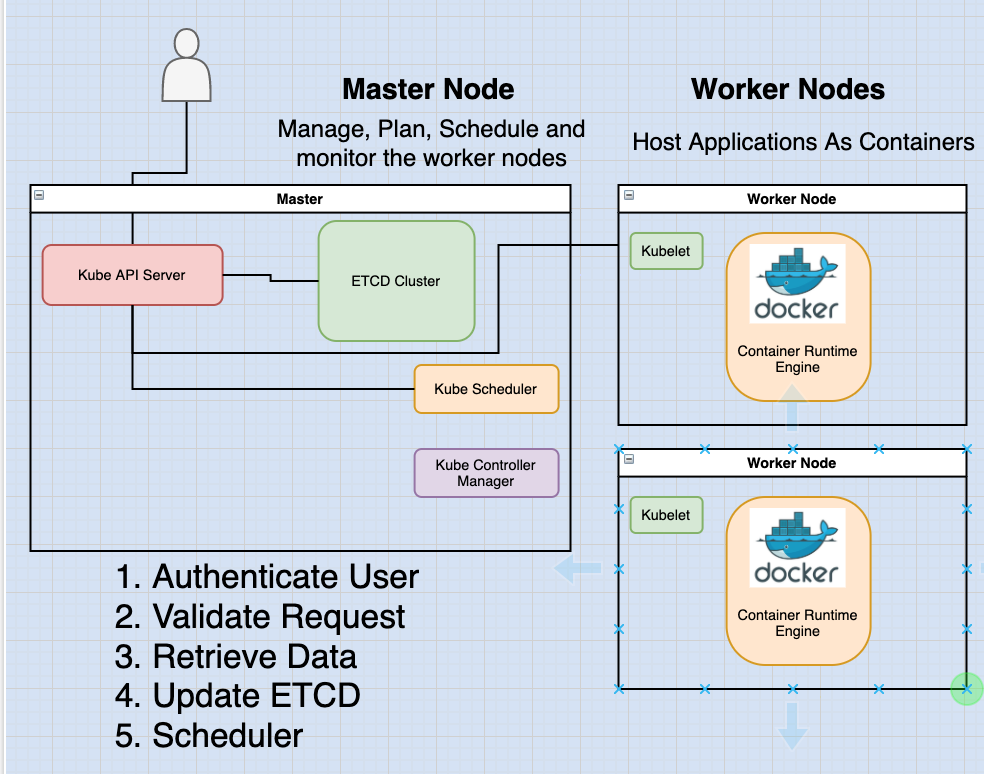
A similar pattern is followed every time a change is requested.
The kube-API server is at the center of all the different tasks that needs to be performed to make a change in the cluster.
Summary
To summarize, the kube-API server is responsible for Authenticating and validating requests, retrieving and updating data in ETCD data store. In fact, kube-API server is the only component that interacts directly with the ETCD datastore.
Following are the steps that the kube-API server takes when a POD is created in the cluster:

The other components such as the scheduler, kube-controller-manager & kubelet, use the API server to perform updates in the cluster in their respective areas.
Throughout this series we are going to take a look at how to install and configure these individual components of the kubernetes architecture.
For now, having a high level understanding will make it easier later when we configure the whole cluster and all of its components from scratch.
The kubernetes architecture consists of a lot of different components working with each other in many different ways, so they all need to know where the other components are.
Authentication
There are different modes of authentication, authorization, encryption and security. And that’s why you have so many options.
Let's look at a few important ones.
A lot of them are certificates that are used to secure the connectivity between different components.
We look at these certificates in more detail when we go through the SSL/TLS certificates section later in this series. So we will not focus on them for now.
But remember, all of the various components we are going to look at in this section will have certificates associated with them.
So how do you view the kube-API server options in an existing cluster?
It depends on how you set up your cluster.
If you set it up with kubeadm tool, kubeadm deploys the kube-API server as a pod in the kube- system namespace on the master node.
You can see the options within the pod definition file located by running the following command:
cat /etc/kubernetes/manifests/kube-apiserver.yamlIn a non-kubeadm setup:
cat /etc/systemd/system/kube-apiserver.serviceYou can also see the running process and the effective options by listing the process on the master node and searching for kube-API server.
ps -aux | grep kube-apiserver