All you need to know to get started with the Kube Scheduler (Kubernetes)
Let's talk about the Kube Scheduler in Kubernetes.
After reading this article you will have:
- Understood the kube scheduler at a high level.
- Installed the kube scheduler.
If you want a refresher on the overall architecture of the kubernetes cluster, I recommend you check out my previous article, as it will help you get the most out of this post. Link Here
The kubernetes scheduler is responsible for scheduling pods on nodes.
Now, just to be clear, the scheduler is only responsible for deciding which pod goes on which node. It doesn’t actually place the pod on the nodes, that would be the responsibility of the kubelet.
The kubelet or the "captain" on the ship (node) is who creates the pod on the ships. The scheduler only decides which pod goes where.
Why do you need a scheduler?
When there are many ships and many containers, You want to make sure that the right container ends up on the right ship.
In kubernetes terms: You want to assure that the right PODs end up on the appropriate nodes.
For example:
- There could be different sizes of ships and containers.
- You want to make sure the ship has sufficient capacity to accommodate those containers.
- Different ships may be going to different destinations.
You want to make sure your containers are placed on the right ships so they end up in the right destination.
As mentioned, in kubernetes, the scheduler decides which nodes the PODs are placed on depending on certain criteria:
- You may have PODs with different resource requirements,
- You can have nodes in the cluster dedicated to certain applications.
How does the scheduler assign these PODs?
The scheduler looks at each individual POD and tries to find the best node for it to be hosted on.
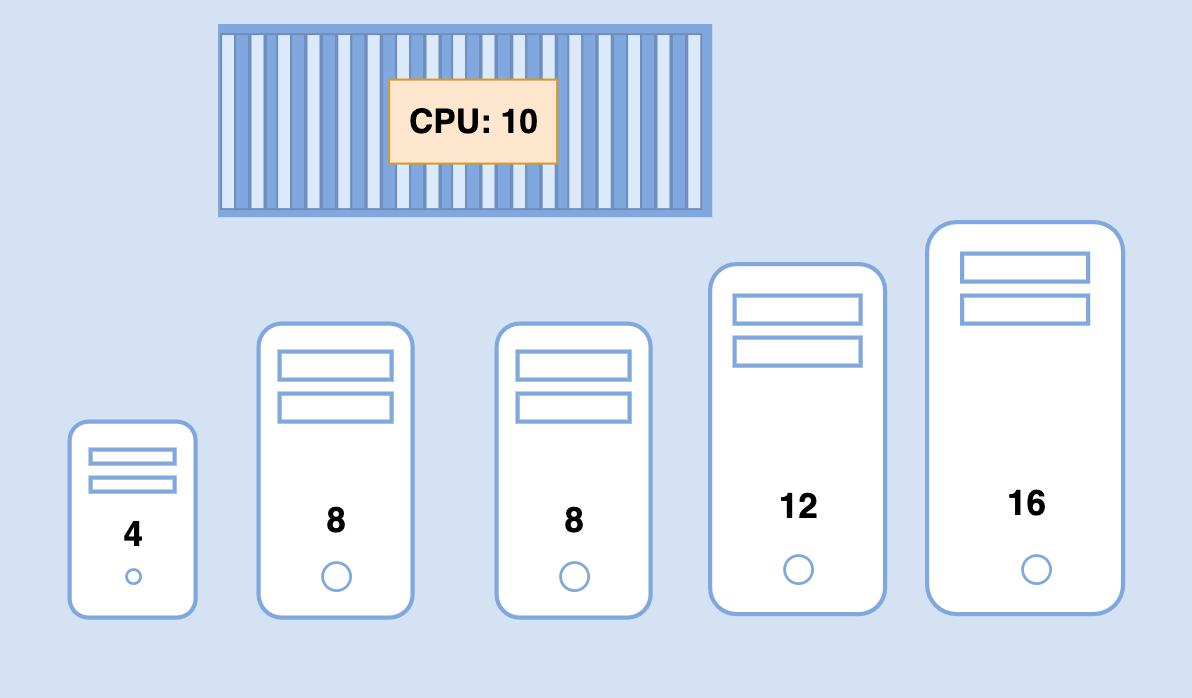
Let's take a look at an example to illustrate:
The big blue POD has a set of CPU and Memory requirements depicted above.
The scheduler goes through two phases to identify the best node for the pod:
The scheduler tries to filter out the nodes that do not fit the profile for this pod.
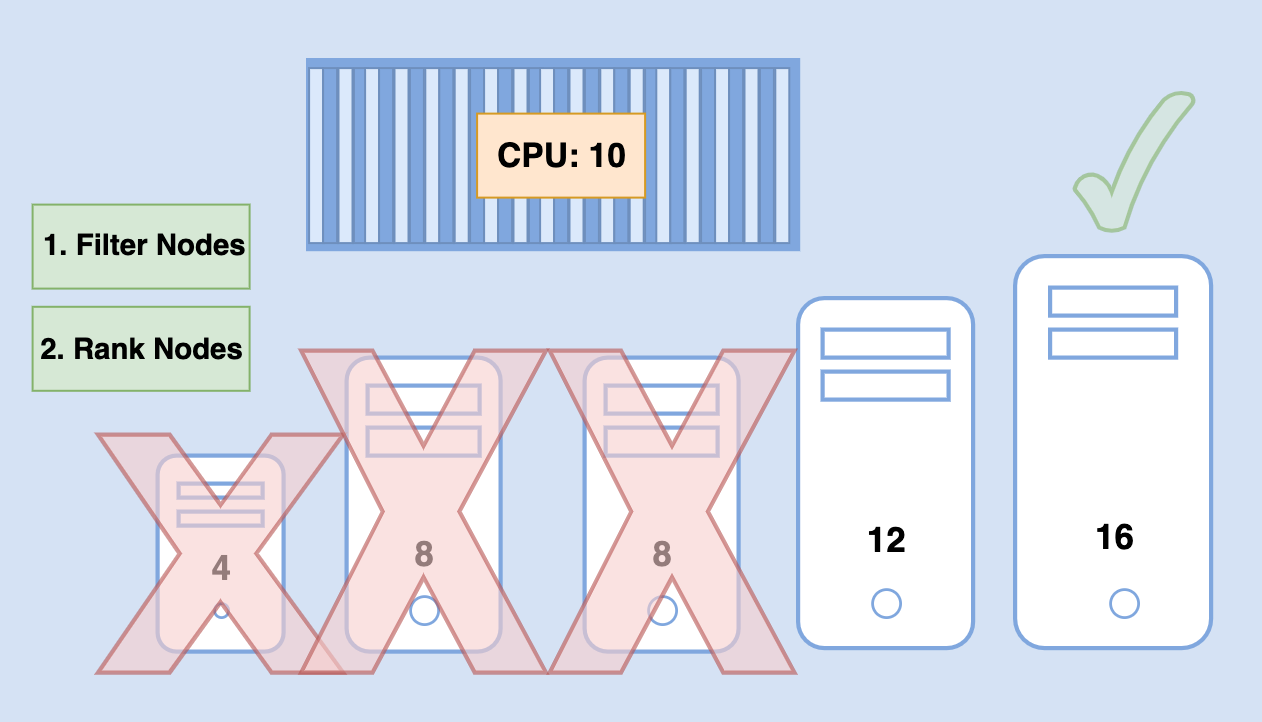
The scheduler ranks the node to identify the best fit for the pod.
For the first step, the nodes that do not have sufficient CPU and memory resources requested by the pod are discarded.
So the first three small nodes are filtered out. We are now left with two nodes on which the POD can be placed.
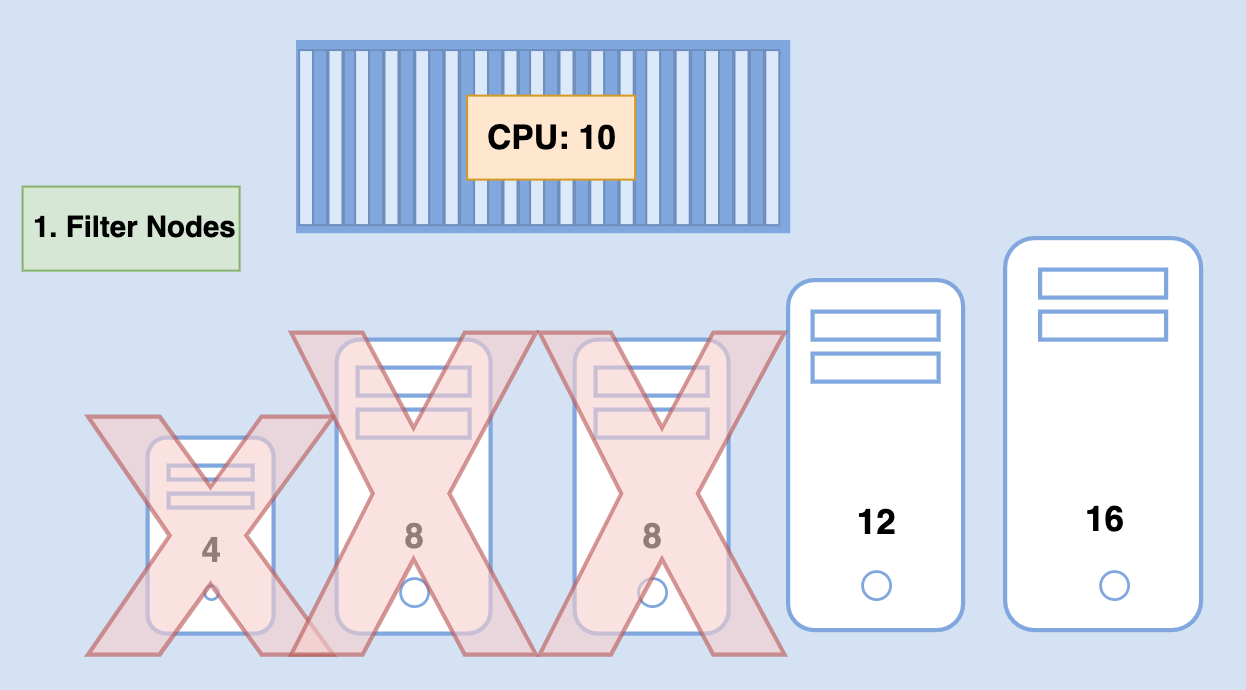
Now, how does the scheduler pick one from the remaining two pods?
In the second step, a priority function is used to assign a score to the nodes on a scale of 0 to 10.
The scheduler calculates the amount of resources that would be free on the nodes after placing the pod on them.
In this case, the one on the right would have 6 CPUs free if the pod was placed on it which is 4 more than the other one so it gets a better rank.
And so it wins.
So that's how a scheduler works at a high level.
In addition, these can be customized and you can write your own scheduler as well.
There are many more topics in scheduling to discuss such as:
- Resource requirements
- Limits
- Taints and tolerations
- Node selectors
- Affinity rules
These will be covered in much more detail in upcoming posts.
For now, we will continue to focus on the scheduler at a high level.
How do you install the kube-scheduler?
Download the kube-scheduler from the kubernetes release page. Extract it and run it as a service:
wget https://storage-googleapis.com/kubernetes-release/release/v1.13.0/bin/linux/amd64/kube-schedulerkube-scheduler.serviceHow do you view the kube-scheduler server options?
If you set it up with kubeadm tool, kubeadm deploys the kube-scheduler as a pod in the kube-system namespace on the master node.
You can see the options within the pod definition file located at:
cat /etc/kubernetes/manifests/kube-scheduler.yamlAlso, you may see the running process and the effective options by listing the process on the master node and searching for kube-scheduler.
ps -aux | grep kube-scheduler